
This is the official implementation of FlashOptim: Optimizers for Memory Efficient Training
By Jose Javier Gonzalez Ortiz, Abhay Gupta, Christopher Rinard, and Davis Blalock.


FlashOptim is a library implementing drop-in replacements for PyTorch optimizers that substantially reduces training memory by shrinking the footprint of optimizer states, master weights, and gradients.
For example, for finetuning an 8B model, FlashOptim requires 35% less peak memory and produces checkpoints that are 57% smaller.
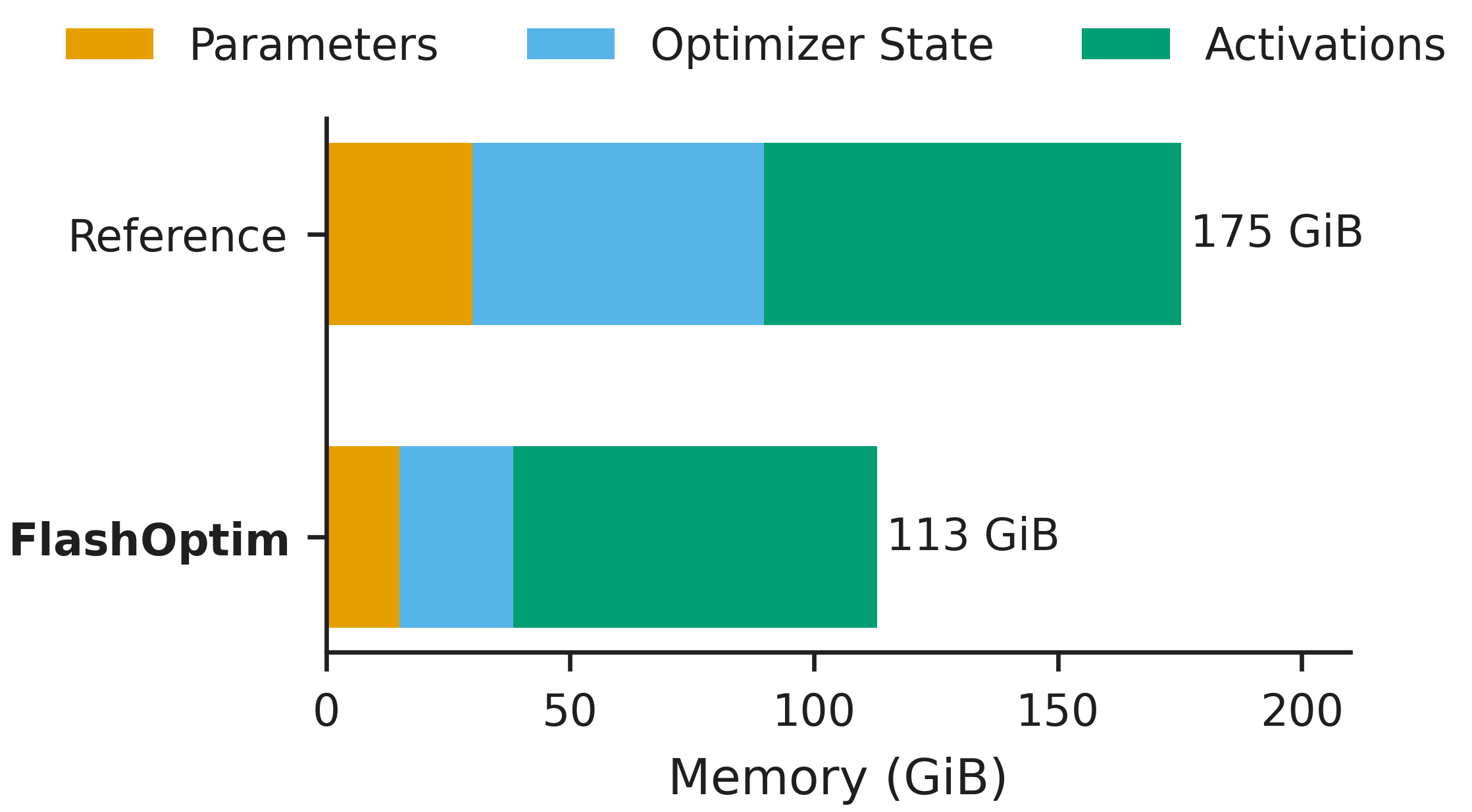
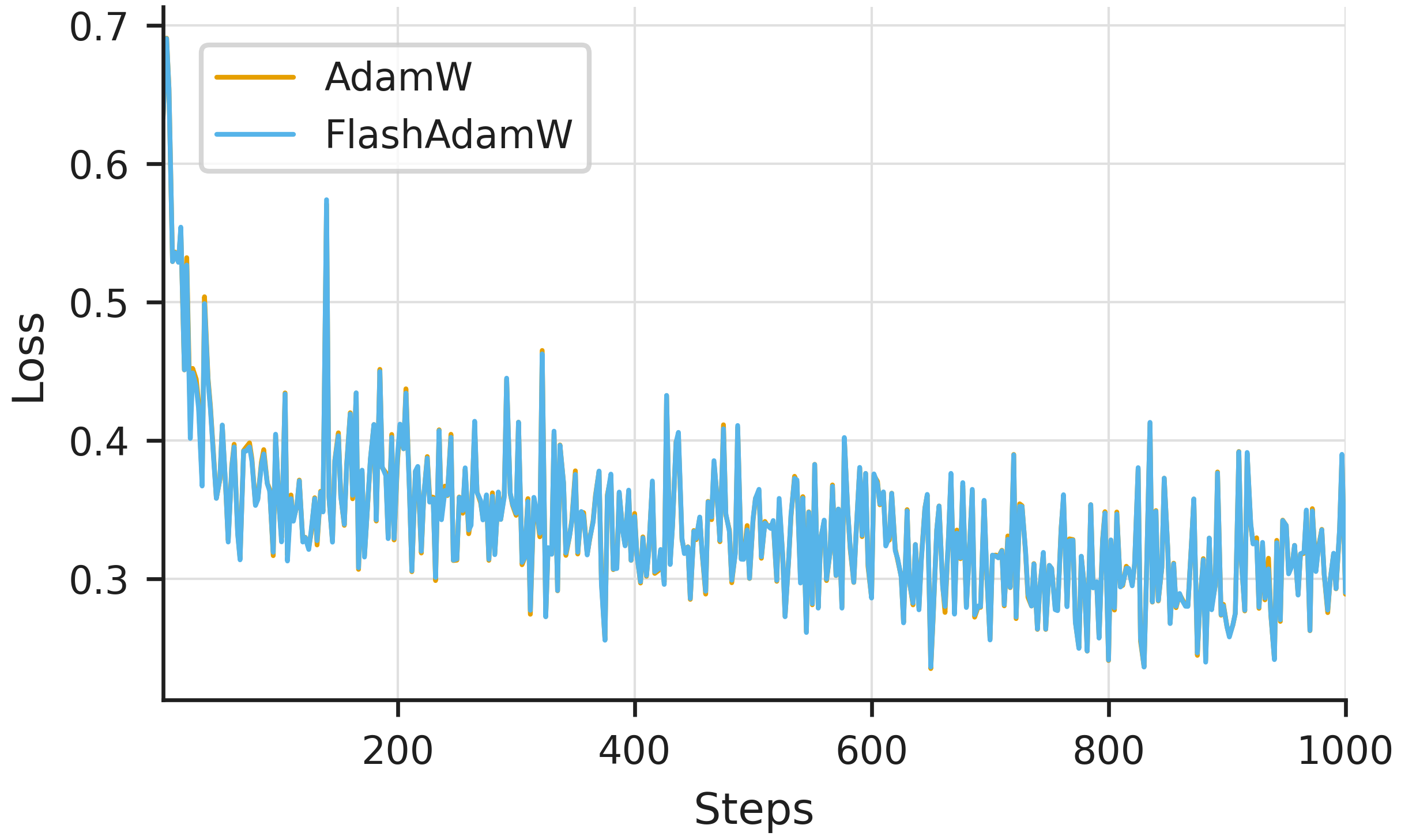
Despite operating in reduced precision, FlashOptim does not affect model convergence.
To get started you can install flashoptim:
$ pip install flashoptimOnce installed, you can import FlashSGD, FlashSGDW, FlashAdam, FlashAdamW and FlashLion, which follow the standard PyTorch optimizer API. For example, to use FlashAdamW:
import torch
from torch import nn
from flashoptim import FlashAdamW, cast_model
model = nn.Sequential(nn.Linear(128, 256), nn.ReLU(), nn.Linear(256, 10)).cuda()
# cast parameters to bf16
cast_model(model, dtype=torch.bfloat16)
# master_weight_bits=24 (default) means we have 24-bit parameter semantics
optimizer = FlashAdamW(model.parameters(), lr=1e-3)
x = torch.randn(32, 128, device="cuda", dtype=torch.bfloat16)
loss = model(x).sum()
loss.backward()
optimizer.step()
optimizer.zero_grad()That's it! You are now training with 50% less per-parameter memory! For more details on the API and advanced features, keep reading.
- Memory Savings. By splitting the weight representation and quantizing the optimizer states, FlashOptim reduces per-parameter memory (e.g. 57% for Adam) and peak training memory without degrading convergence.
- Fused Triton Kernels. All compression operations are fused into the update kernel, introducing no practical overhead.
- Gradient Release. Optionally, parameters can be updated as soon as the gradients are computed, further reducing peak memory.
- Compressed Checkpoints. Checkpoints can optionally be stored using quantized optimizer states, producing >50% space savings.
- PyTorch API. The optimizers follow the standard
torch.optim.Optimizerinterface.
FlashOptim can be installed using pip or uv. Note that FlashOptim is only supported on Linux systems with NVIDIA CUDA GPUs.
# install stable version
pip install flashoptim
# install latest version from source
pip install git+https://github.com/databricks/flashoptim.git
# or install it locally in editable mode for development
git clone https://github.com/databricks/flashoptim.git
cd flashoptim
pip install -e .Note
The first optimizer step will be slower than subsequent steps due to Triton kernel JIT compilation. This is a one-time cost per kernel configuration.
The master_weight_bits parameter controls the width of the master weights maintained by the optimizer. By default, master weights are 24-bit, narrower than fp32, which saves memory. When training in bf16/fp16, the downcasting is fused into the update kernel, so no separate cast step is needed:
from flashoptim import FlashAdamW
# Default: 24-bit master weights (bf16 param + 8-bit correction term)
optimizer = FlashAdamW(model.parameters(), lr=1e-3)
# 32-bit master weights (bf16 param + 16-bit correction term)
optimizer = FlashAdamW(model.parameters(), lr=1e-3, master_weight_bits=32)
# No master weight correction; parameters stay at native precision
optimizer = FlashAdamW(model.parameters(), lr=1e-3, master_weight_bits=None)The exact behavior depends on the dtype of the parameters passed to the optimizer:
- bf16/fp16 parameters: Optimizer states (moments) are quantized to 8-bit. The
master_weight_bitssetting controls master weight precision and fuses the downcasting into the update kernel:master_weight_bits=24(default): 8-bit correction terms for 24-bit master weights, narrower than fp32 while preserving convergencemaster_weight_bits=32: 16-bit correction terms for full 32-bit master weight semanticsmaster_weight_bits=None: no master weight correction; optimizer states are still quantized, but parameters stay at their native precision
- fp32 parameters: Optimizer states (moments) are quantized to 8-bit to reduce memory. Parameters are already full precision, so
master_weight_bitsis not applicable.
To cast a model's parameters and buffers to bf16, use the cast_model helper. cast_model uses keyword matching against module names to determine which layers to keep in full precision, by default, normalization layers are kept in fp32 for training stability. It also registers forward pre-hooks on fp32 modules to automatically upcast their inputs during the forward pass:
from flashoptim import cast_model
# Cast all parameters to bf16 (normalization layers kept in fp32 by default)
cast_model(model, dtype=torch.bfloat16)
# Keep specific layers (e.g., the output head) in fp32
cast_model(model, dtype=torch.bfloat16, full_precision_keywords=["lm_head", "head"])Note
Keywords are matched against dot-separated name segments, so "head" matches model.head.weight but not model.header.weight.
FlashOptim follows PyTorch's convention of separating L2 regularization from decoupled weight decay via separate classes:
| Optimizer | Weight Decay Style | PyTorch Equivalent |
|---|---|---|
FlashAdam |
L2 regularization (coupled) | torch.optim.Adam |
FlashAdamW |
Decoupled | torch.optim.AdamW |
FlashSGD |
L2 regularization (coupled) | torch.optim.SGD |
FlashSGDW |
Decoupled | - |
FlashLion |
Decoupled | - |
For decoupled optimizers (FlashAdamW, FlashSGDW, FlashLion), weight decay is applied as a multiplicative factor on the parameters, matching PyTorch's AdamW semantics:
This means FlashAdamW(params, lr=1e-3, weight_decay=0.01) is equivalent to torch.optim.AdamW(params, lr=1e-3, weight_decay=0.01).
Setting decouple_lr=True enables fully LR-decoupled weight decay, where
At initialization weight_decay values than with PyTorch. For example, if you were using torch.optim.AdamW(params, lr=1e-3, weight_decay=0.01) (effective decay FlashAdamW(params, lr=1e-3, weight_decay=1e-5, decouple_lr=True).
The LR-decoupled formulation ensures that weight decay remains stable regardless of learning rate schedule changes. See Loshchilov & Hutter (2019) and Schaipp (2024) for more details on decoupling LR and WD magnitudes.
FlashOptim represents full-precision parameters using two components:
- Low precision parameters. These are stored as
nn.Moduletensors. - Error correction terms. These are stored as optimizer state tensors under the
"error_bits"key inoptimizer.state[param].
FlashOptim provides methods for exporting and importing full-precision (FP32) checkpoints. For loading, the model must have been initialized with the desired precision (e.g. via cast_model).
import torch
import torchvision
from flashoptim import FlashAdamW, cast_model
model = torchvision.models.resnet18().cuda()
cast_model(model, dtype=torch.bfloat16, full_precision_keywords=["fc"])
optimizer = FlashAdamW(model.parameters(), lr=1e-3, master_weight_bits=24)
# ... training ...
# Save: reconstruct fp32 from bf16 + error bits
fp32_state_dict = optimizer.get_fp32_model_state_dict(model)
torch.save(fp32_state_dict, "checkpoint.pt")
# Load: restore fp32 weights into a bf16 model (error bits recomputed automatically)
fp32_state_dict = torch.load("checkpoint.pt", weights_only=True)
optimizer.set_fp32_model_state_dict(model, fp32_state_dict)By default, optimizer state dicts are saved with states cast to bf16, which is already smaller than fp32. For additional savings, set compress_state_dict=True when constructing the optimizer to quantize states to int8, producing checkpoints ~50% smaller than bf16:
# Default: state_dict() saves states as bf16
optimizer = FlashAdamW(model.parameters(), lr=1e-3)
torch.save(optimizer.state_dict(), "checkpoint_bf16.pt")
# Compressed: state_dict() saves states as quantized int8
optimizer = FlashAdamW(model.parameters(), lr=1e-3, compress_state_dict=True)
torch.save(optimizer.state_dict(), "checkpoint_int8.pt")Note
Compressed state dicts are not loadable by vanilla PyTorch optimizers. They can only be loaded back by FlashOptim optimizers using optimizer.load_state_dict().
FlashOptim is compatible with data parallelism strategies including DistributedDataParallel (DDP) and FSDP2. Wrap or shard your model as usual, then pass the resulting parameters to the optimizer:
Warning
FlashOptim does not support FSDP1 (FullyShardedDataParallel) due to design limitations in how FSDP1 manages parameter and optimizer state sharding. Please use FSDP2 (fully_shard) instead.
# DDP
model = DDP(model, device_ids=[device.index])
optimizer = FlashAdamW(model.parameters(), lr=1e-3, master_weight_bits=24)
# FSDP2
fully_shard(model)
optimizer = FlashAdamW(model.parameters(), lr=1e-3, master_weight_bits=24)FlashOptim supports gradient release, which updates parameters during the backward pass as soon as gradients are computed, further reducing memory usage. Gradient release is implemented via post-backward hooks and needs to be enabled explicitly:
from flashoptim import FlashAdamW, enable_gradient_release
optimizer = FlashAdamW(model.parameters(), lr=1e-3, master_weight_bits=24)
handle = enable_gradient_release(model, optimizer)
for x, y in dataloader:
loss = loss_fn(model(x), y)
loss.backward()
# step() and zero_grad() are no-ops while gradient release is active;
# parameters are updated during backward and gradients are freed immediately
optimizer.step()
optimizer.zero_grad()
# Call handle.remove() to restore normal optimizer behavior
handle.remove()Gradient release is compatible with single-GPU training and FSDP2 (fully_shard).
Limitations. Since the parameters are updated during the backward pass and gradients are freed immediately, gradient release is incompatible with:
- DDP. DDP uses custom communication hooks and buffers that cannot be easily instrumented.
- Microbatch Accumulation. Gradient release steps parameters immediately as gradients arrive, so gradients cannot be accumulated.
- Gradient Clipping. Global gradient clipping (e.g.
torch.nn.utils.clip_grad_norm_) cannot be applied. - Gradient Scaling.
torch.amp.GradScaleris not supported with gradient release.
When training in reduced precision, a learning rate that is too small relative to the parameter magnitudes can produce updates that round to zero, silently stalling training.
Setting check_numerics=True detects this: at each step FlashOptim verifies that lr is large enough to actually change the largest values in every tensor (given the parameter dtype and master_weight_bits).
This is useful as a sanity check during early training to catch silent stalls caused by updates that round to zero.
| Requirement | Details |
|---|---|
| Hardware | NVIDIA GPUs with CUDA support |
| OS | Linux |
| Python | ≥3.9 |
| PyTorch | ≥2.7 |
| Triton | ≥2.0 |
| Distributed | DDP and FSDP2 supported; FSDP1 not supported |
| Precision | bf16, fp16, and fp32 parameters |
For contributing to FlashOptim, please see our contributing guidelines.
If you use FlashOptim in your research, please cite our paper:
@article{gonzalezblalock2026flashoptim,
title={FlashOptim: Optimizers for Memory Efficient Training},
author={Gonzalez Ortiz, Jose Javier and Gupta, Abhay and Rinard, Christopher and Blalock, Davis},
journal={arXiv preprint arXiv:2602.23349},
year={2026}
}